CRM support tickets are messy. They reference past interactions, account state, product details — a single ticket might need a knowledge base lookup, a JIRA action, and a coherent response in sequence.
Overview
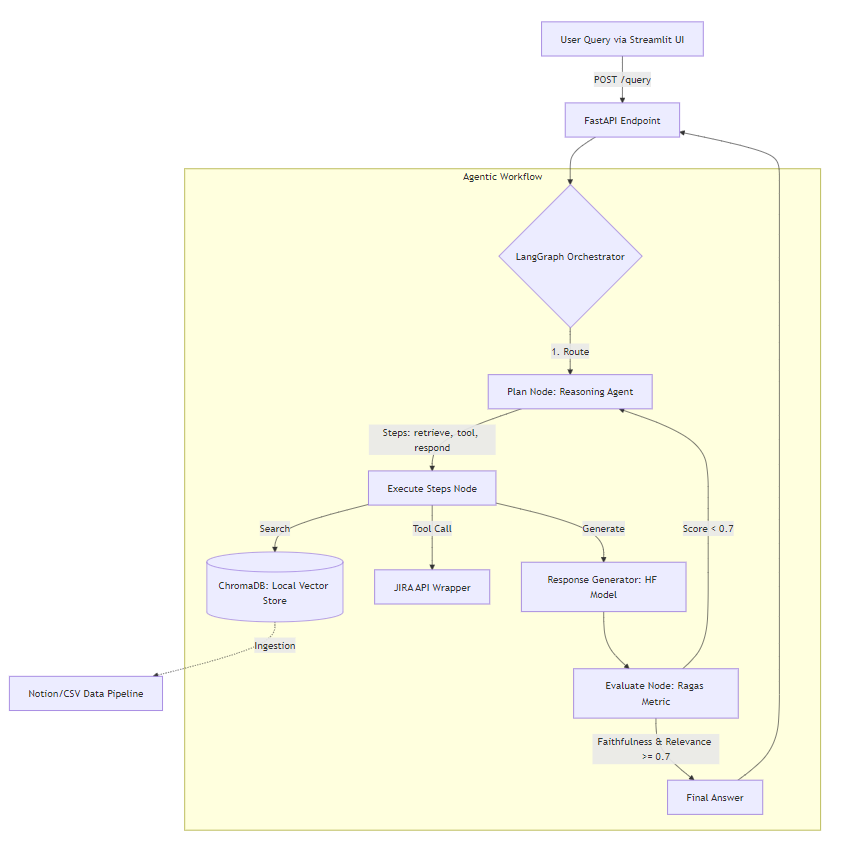
Architecture (condensed)
A support ticket comes in via Gradio UI, hits a FastAPI endpoint, and enters a LangGraph state machine. Three nodes — Plan, Execute, Evaluate — with a conditional edge that loops back if the response doesn't pass quality thresholds.
User Query → FastAPI → LangGraph Orchestrator
│
┌─────────▼──────────┐
│ Plan Node │
│ Reasoning Agent │
│ decides: retrieve │
│ / tool / respond │
└─────────┬──────────┘
│
┌─────────▼──────────┐
│ Execute Node │
│ │
│ ChromaDB RAG │
│ JIRA Tool │
│ HF Generator │
└─────────┬──────────┘
│
┌─────────▼──────────┐
│ Evaluate Node │
│ Ragas metrics │
│ faithfulness + │
│ relevance >= 0.7 │
└─────────┬──────────┘
│
┌───────────────┴──────────────┐
│ pass │ fail
▼ ▼
Final Answer back to PlanWhy LangGraph
The self-correction loop requires a cycle — Evaluate needs to route back to Plan on failure. LangGraph handles this with a cyclic state machine where each node receives and returns a shared AgentState.
from typing import TypedDict, List
class AgentState(TypedDict):
query: str
plan: List[str] # steps: retrieve / tool / respond
retrieved_docs: List[str]
tool_results: List[str]
response: str
eval_scores: dict # faithfulness, relevance
iteration: int # prevent infinite loopsThe conditional edge checks eval_scores and iteration < MAX_RETRIES before deciding whether to route back or exit.
RAG — Local with ChromaDB and BGE
BGE embeddings (BAAI/bge-base-en-v1.5) from HuggingFace — keeps everything local, no external calls during retrieval. I am using BGE embeddings because it is open-source and shows superior performance on MTEB leaderboard.
from sentence_transformers import SentenceTransformer
embedder = SentenceTransformer('BAAI/bge-base-en-v1.5')
def retrieve(query: str, top_k: int = 5) -> List[str]:
query_embedding = embedder.encode(
f"Represent this sentence for searching: {query}"
)
results = collection.query(
query_embeddings=[query_embedding.tolist()],
n_results=top_k
)
return results['documents'][0]BGE is trained with instruction prefixes — "Represent this sentence for searching:" is required for retrieval queries, not passage encoding.
Self-Correction with Ragas
Ragas evaluates RAG output without ground truth labels. Two metrics:
Faithfulness — every claim in the response must be traceable to the retrieved documents. Catches hallucination.
Answer Relevance — the response must address the actual query. Catches topic drift.
from ragas.metrics import faithfulness, answer_relevancy
from ragas import evaluate
from datasets import Dataset
def evaluate_response(query, response, contexts) -> dict:
data = Dataset.from_dict({
"question": [query],
"answer": [response],
"contexts": [contexts],
})
result = evaluate(data, metrics=[faithfulness, answer_relevancy])
return {
"faithfulness": result["faithfulness"],
"relevance": result["answer_relevancy"]
}If either score is below 0.7, the state routes back to Plan with the scores attached. The reasoning agent uses this as signal to adjust retrieval or regeneration strategy on the next iteration.
JIRA Tool
When Plan decides a ticket needs to be created or queried, it emits tool as a step. Execute calls this:
def create_jira_ticket(summary: str, description: str, issue_type: str = "Bug") -> dict:
payload = {
"fields": {
"project": {"key": JIRA_PROJECT_KEY},
"summary": summary,
"description": description,
"issuetype": {"name": issue_type}
}
}
response = requests.post(
f"{JIRA_BASE_URL}/rest/api/2/issue",
json=payload,
auth=(JIRA_EMAIL, JIRA_API_TOKEN)
)
return response.json()The agent decides when to call this based on ticket content — not a hardcoded trigger.
Stack
Python, LangGraph, LangChain, ChromaDB, HuggingFace (Transformers + BGE), Ragas, FastAPI, Docker, LangSmith for tracing.