Audio QC at scale is not a pure classification problem. It sits at the intersection of signal processing, perception, and system design.
This project focuses on detection, but correctness in production depends on factors beyond the model: perceptual salience of artifacts, temporal consistency across streams, and how efficiently a human can verify flagged segments.
I approached this as a data-centric, DSP-informed pipeline, not just a model training task.
All iterations (10–15 cycles, primarily data-focused), metric transitions, and failure modes were tracked in Obsidian Canvas to keep decisions explicit and reproducible.
Problem
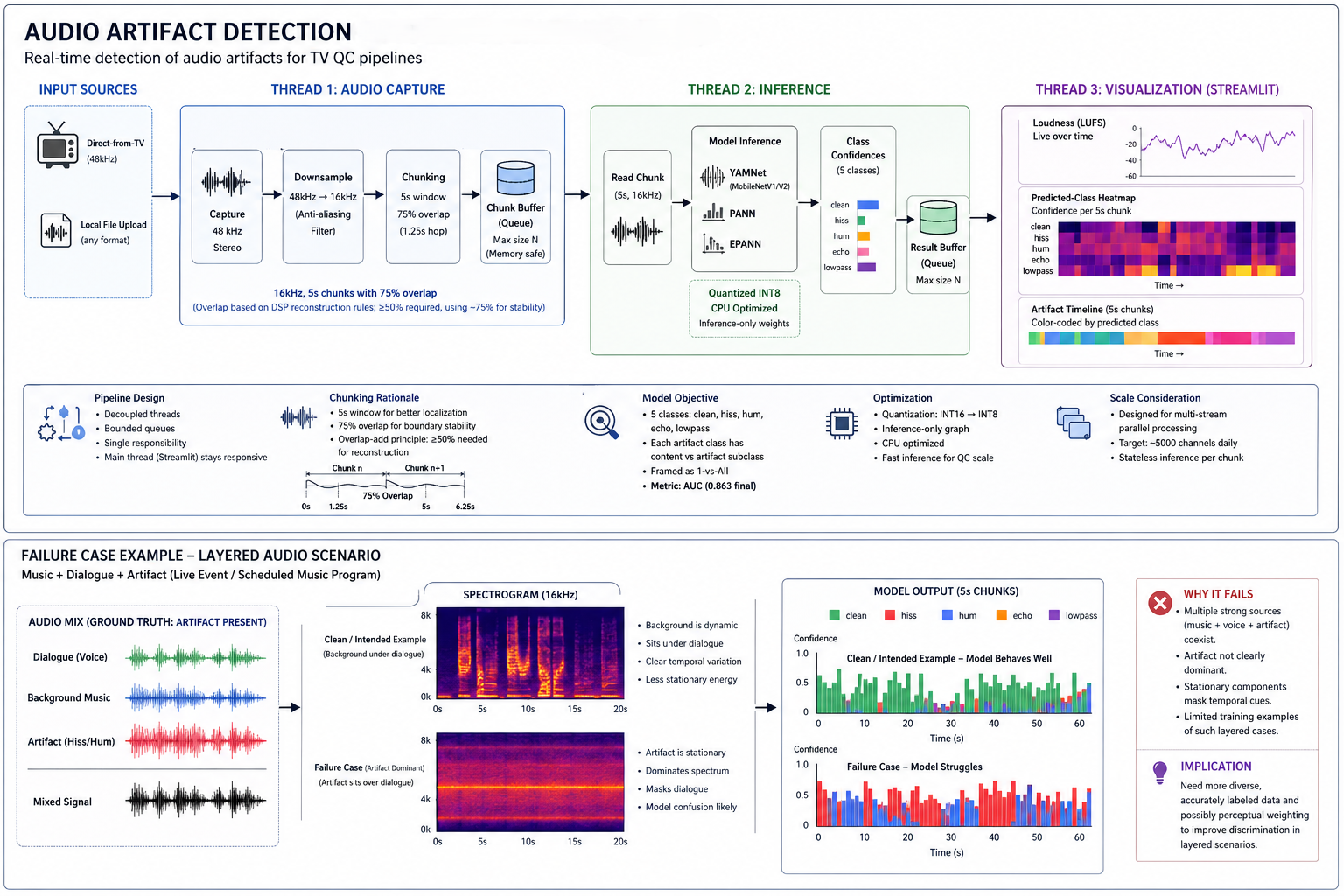
Live TV channels, events, and VOD streams routinely carry audio artifacts—hiss, hum, echo, lowpass filtering, glitches, crackles. QC teams detect these manually by scanning timelines.
The goal was to detect artifacts in near real-time and surface them in a way that minimizes human verification effort.
Dataset Construction
The dataset was built from scratch using 100 raw TV recordings (~4 hours each) across channels, genres, and languages. Diversity was intentional—artifact behavior changes significantly over speech, music, and mixed content.
Audio was downsampled to 16 kHz, segmented into 5-second chunks, and filtered to remove silence using spectral flatness and dynamic range thresholds. Silence removal was necessary to avoid skewing the distribution and inflating model confidence.
A critical validation step was ensuring that downsampling preserved artifact characteristics. Using Fourier windowing and spectrogram comparisons before and after resampling, I verified that class-defining patterns remained intact. This is especially important for artifacts like lowpass filtering, which can shift perceptually under improper resampling.
The final dataset consisted of ~10,000 labeled segments.
Class Design
The model operates on five classes: clean, hiss, hum, echo, and lowpass. Each artifact class was further split into content and artifact subclasses to distinguish intentional sound design from degradation.
A key observation from signal behavior guided this design:
In dialogue-heavy audio, intended background noise is dynamic and sits beneath the voice, while artifacts tend to be more stationary, dominant, and often override the foreground signal.
Instead of treating this as a strict multi-class problem, it was reframed as:
artifact vs non-artifact (1-vs-All)
This introduces an asymmetric constraint: missing an artifact is costly, while misclassifying intentional content as clean is acceptable. Under this framing, AUC becomes the correct metric, not accuracy.
Model Development
Model development went through 10–15 iterations, with most gains coming from data refinement rather than architectural changes.
Backbones included YAMNet (MobileNetV1/V2), PANN, and EPANN. Iterations focused on improving dataset quality—refining silence thresholds, correcting ambiguous labels, rebalancing classes, and inspecting failure cases through spectrogram analysis.
Metric selection evolved alongside understanding. Initial experiments used accuracy, but it proved unreliable for continuous audio streams and imbalanced data. The system ultimately relied on AUC, which better captures discrimination across thresholds.
Instead of binary outputs, predictions were treated as confidence distributions per chunk, allowing more stable and interpretable detection when mapped over time.
The final model achieved 0.863 AUC on a held-out test set.
Temporal Design & Chunking
Audio was processed in 5-second chunks with ~75% overlap.
Chunk duration was informed by prior work (e.g., Amazon’s use of longer windows), but reduced to 5 seconds to better localize artifacts without losing context. Shorter windows improved responsiveness while still capturing enough temporal structure.
Overlap was introduced based on DSP reconstruction principles. While ~50% overlap is typically sufficient for overlap-add reconstruction, increasing this to ~75% reduced boundary artifacts and improved stability of predictions across chunk edges.
This design helped mitigate discontinuities introduced by chunking in a continuous signal.
DSP Integration
Signal-level reasoning guided both dataset construction and modeling decisions.
- Spectral flatness and dynamic range were used for silence detection
- Spectrograms were used to validate both data and model failures
- Downsampling was explicitly verified for class preservation
A useful working heuristic emerged:
Artifacts tend to be stationary and dominant, while intended audio remains dynamic and structured beneath the foreground.
This insight consistently explained model successes and failures.
Failure Modes
The model struggles in layered audio scenarios, particularly where:
- speech
- background music
- and artifacts
coexist simultaneously (e.g., live events or scheduled music programming).
In these cases, artifacts do not clearly dominate the signal, making discrimination harder. This highlights a limitation of current labeling and suggests the need for more granular or perceptually weighted approaches.
Inference Optimization
The model was designed for CPU deployment within a QC pipeline.
It was quantized from INT16 to INT8 and stripped down to inference-only components. This reduced model size and improved latency with minimal loss in performance.
Runtime System
The system operates as a streaming pipeline with decoupled stages.
Audio is captured at 48 kHz, downsampled to 16 kHz, chunked, and processed asynchronously. A bounded queue manages buffers to prevent memory growth during long sessions.
Separate threads handle capture, inference, and visualization, keeping the system responsive and stable.
Visualization
A Streamlit dashboard was built for usability.
It supports both live TV input and local files, and provides:
- loudness tracking (LUFS)
- class confidence heatmaps
- artifact timelines
The timeline proved most effective, enabling direct navigation to flagged segments.
Outcome
The system was demonstrated across internal QC teams, US stakeholders, and cross-functional reviews.
It was selected for integration as a pre-analysis module in the QC automation pipeline.
Discussions post-demo focused on scaling the system to process thousands of channels in parallel, highlighting the need for distributed inference and efficient stream handling.
Future Work
Next steps are less about model accuracy and more about alignment with perception and scale:
- perceptual weighting of artifacts
- temporal smoothing across segments
- improved labeling for layered audio
- distributed inference across large channel volumes
Closing
This project is best understood as a system.
It combines DSP validation, data-centric iteration, optimized inference, and real-time pipeline design. The primary gains came not from changing architectures, but from understanding the signal and shaping the data accordingly.