A small idea that stayed
This started as a simple thought experiment while I was on a train, trying to pass time. I was thinking about how a 3D room could be represented in a way that is both spatially meaningful and computationally efficient. One idea led to another — from grids, to octrees, to memory layout — and eventually it connected to something I’ve been curious about for a while: spatial audio.
This is not a polished system, and not a novel contribution. It’s closer to a partially explored direction that I’ve tried to implement just enough so that it becomes inspectable. I’m sharing it in that spirit.
The core intuition
At a very basic level, the idea is to take a 3D room and turn it into something that the system can traverse efficiently.
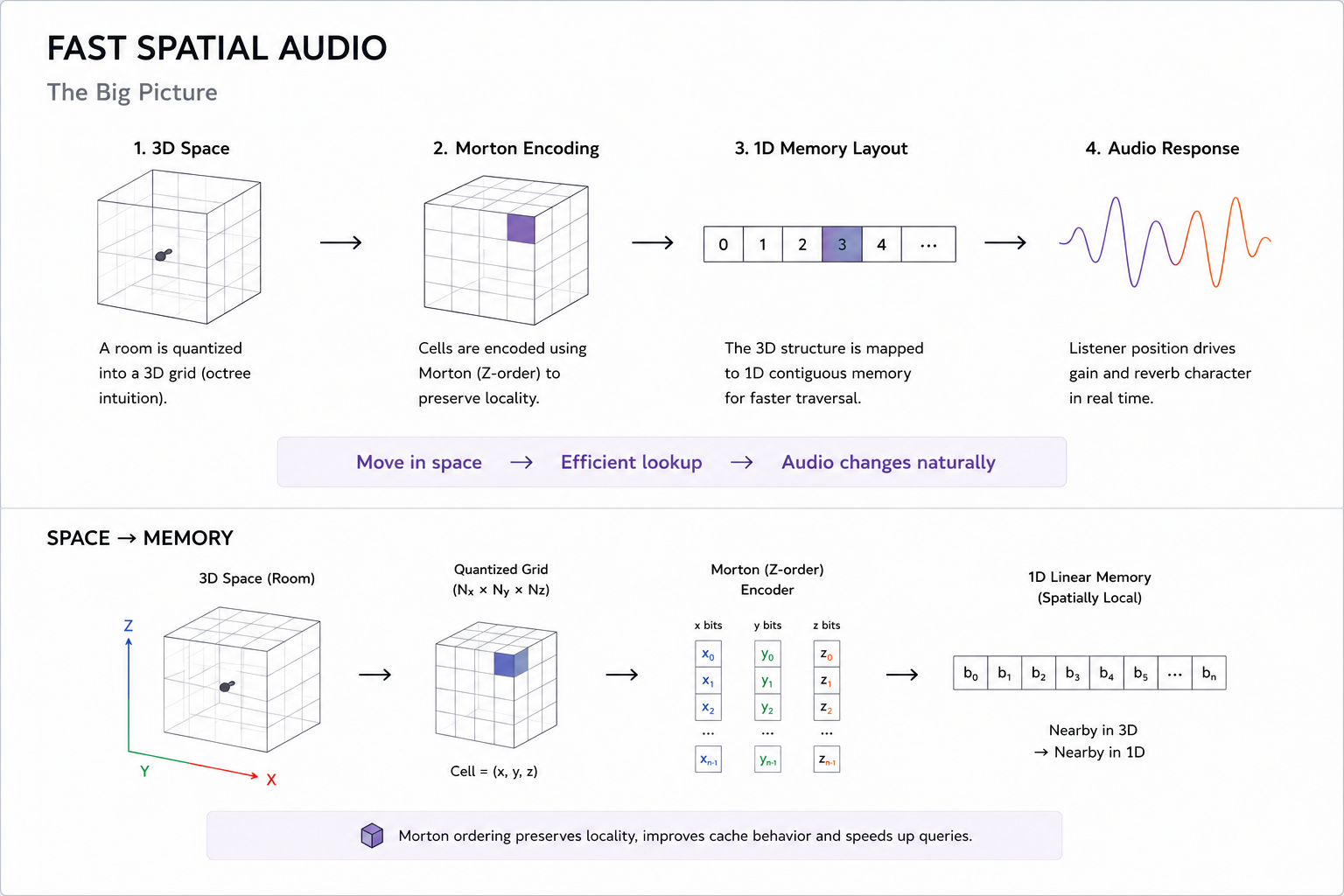
Instead of treating space as continuous, I quantize it into a grid. That grid can be thought of as an octree (outlined in barebones-ml), where each cell represents a region in space. The interesting part comes when trying to store and traverse this efficiently.
If we naively store 3D data, we lose spatial locality in memory. So I experimented with mapping this 3D structure into a 1D layout using Morton (Z-order) encoding. The expectation here is simple: points that are near in 3D should, as much as possible, also be near in memory.
This becomes relevant when something moves through space — like a listener. If movement translates to predictable memory access patterns, then traversal and lookup become cheaper and more stable.
At this point, it was still just a spatial data experiment.
Where audio came in
The next step was: if I already have a notion of “where the listener is” in a structured space, can I make the system respond to it in a perceptible way?
That’s where spatial audio came in.
Instead of going into physically accurate simulation, I chose a simpler and more controllable approach: convolution with impulse responses (IRs). I used two different acoustic profiles — something like a cathedral and a corridor — and blended between them based on position.
So now the system does something intuitive:
As the listener moves through space, the sound changes — not just in volume (distance attenuation), but also in character (reverb profile).
This is inspired loosely by concepts like zones, portals, and blends used in game audio systems (e.g., Wwise), but implemented in a much simpler form.
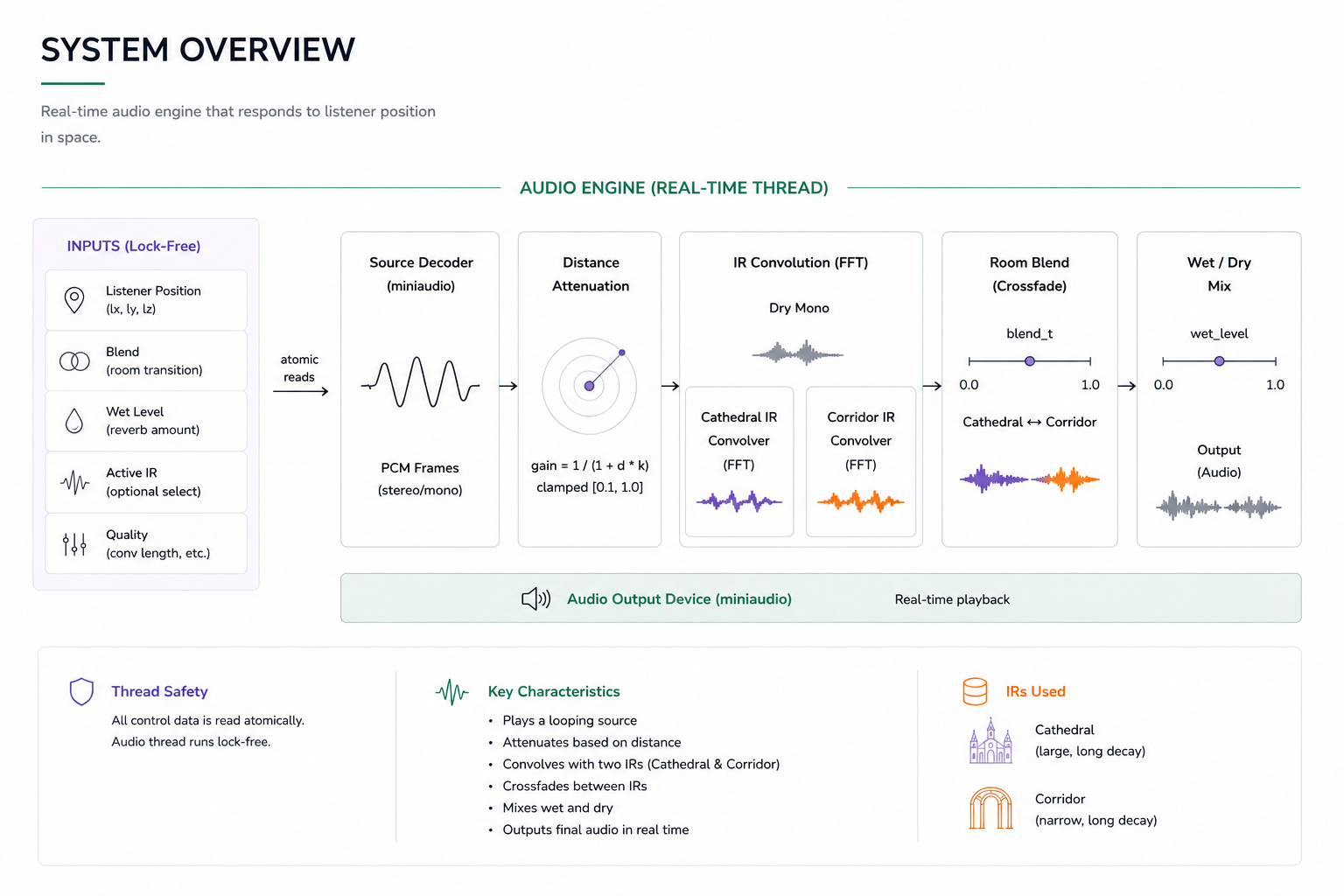
What the system currently does
There are two main parts running together.
On one side, there is a spatial layer:
- A quantized 3D room
- Morton encoding to map it into 1D memory
- A listener position that moves through this space
On the other side, there is an audio engine:
- A looping audio source
- Distance-based attenuation
- Two FFT-based convolvers (for two IRs)
- A blend parameter that crossfades between them
- Wet/dry mixing
All runtime parameters are updated through a small atomic state structure, so the audio thread can run without locks (which could cause pops and stutters)
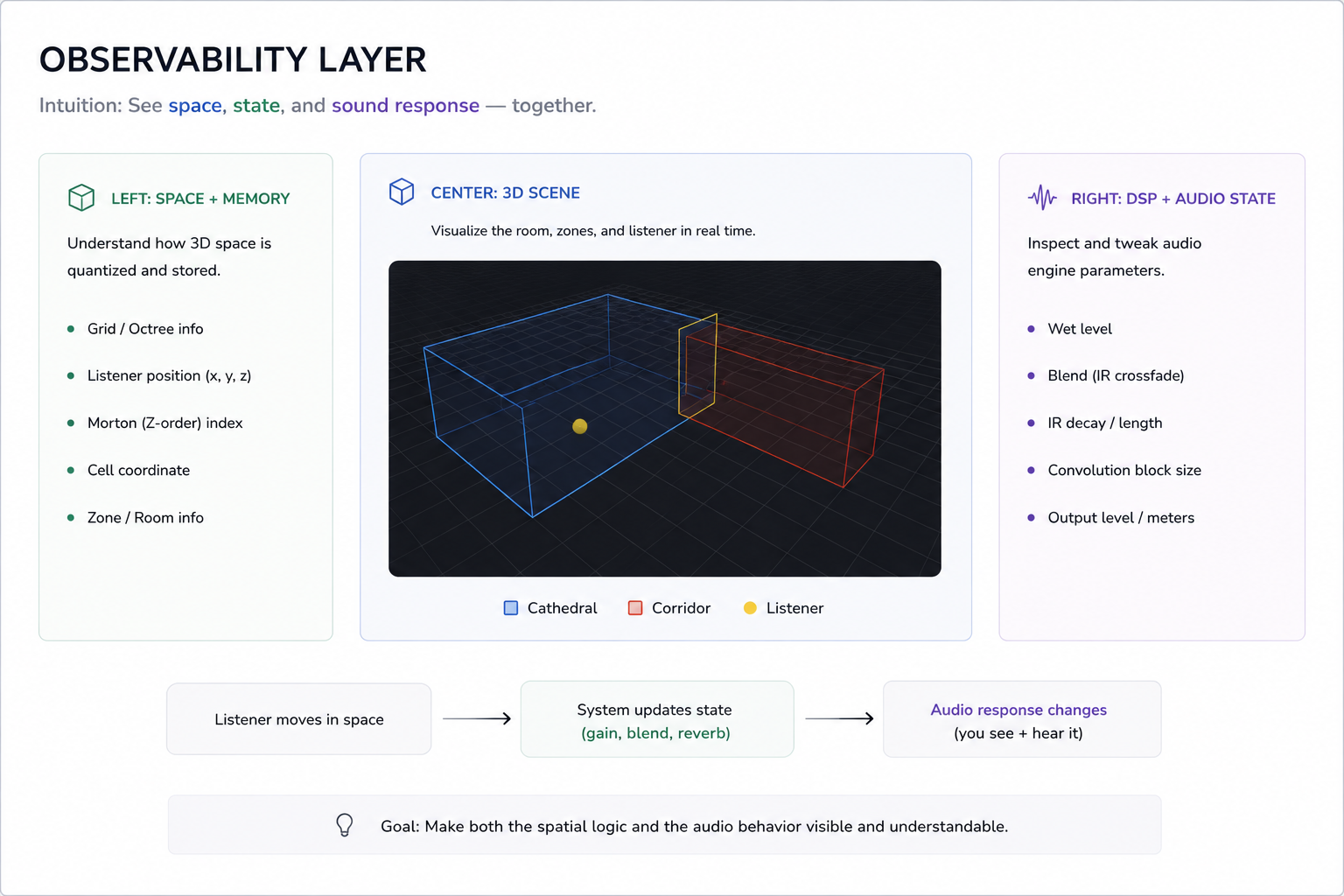
About the visualization
The current UI is not meant to be a product interface. It is more of an observability layer for the system.
On the left, it shows spatial and memory-related details — including the Morton code and some basic octree stats.
On the right, it shows DSP-related parameters like wet level, decay, and convolution block size.
In the center, there is a simple 3D scene with two zones (cathedral and corridor) and a listener point moving inside them.
The idea is to make both the spatial logic and the audio response visible at the same time.
What I am unsure about
There are quite a few things here that I don’t fully understand or haven’t validated properly.
I am not sure how much the Morton layout is actually helping in this context, or if it is just an interesting but unnecessary abstraction at this stage.
The audio model is also simplified. Blending between two impulse responses works perceptually, but I don’t know how meaningful it is from a physical or acoustics standpoint.
The connection between spatial indexing and audio response is also quite loose right now. It works, but it’s not deeply integrated.
Even at the code level, there are parts — especially around the DSP pipeline and convolution setup — where I would appreciate a deeper review.
Why I am sharing this
I wanted to take this idea to a point where it is no longer just conceptual, but something that can be read, run, and questioned.
If you are someone who works with:
- audio systems or DSP
- spatial data structures
- real-time systems
- or even game/audio engine design
I would really appreciate your perspective.
Some questions I personally have:
- Does mapping space with Morton order make sense here, or is it premature?
- Is dual-IR blending a reasonable approximation for spatial transitions?
- Is there a better way to connect spatial structure to audio behavior?
Even a quick audit, critique, or direction would be helpful.
Closing
This is still a work in progress and very much an exploration. If nothing else, it helped me connect ideas from spatial data structures, memory layout, and audio processing in a single system.
If it sparks any thoughts or if something looks off, I’d be glad to discuss.