A note before we start — technically, heavy audio dsp should be done in c++ and compiled to wasm for js. but a loudness meter is not computationally heavy. the webaudio api with audioworklet is sufficient here, and that's what we used.
The problem
loudness qc is a real problem in broadcast and streaming. tracks that measure fine digitally cause distortion on playback hardware. platforms mandate integrated loudness targets (-14 lufs for spotify, -16 lufs for youtube) and true peak ceilings (-1 dbtp). doing this manually is slow. doing it in a browser, in real-time, with no backend — that's the interesting part.
High Level overview
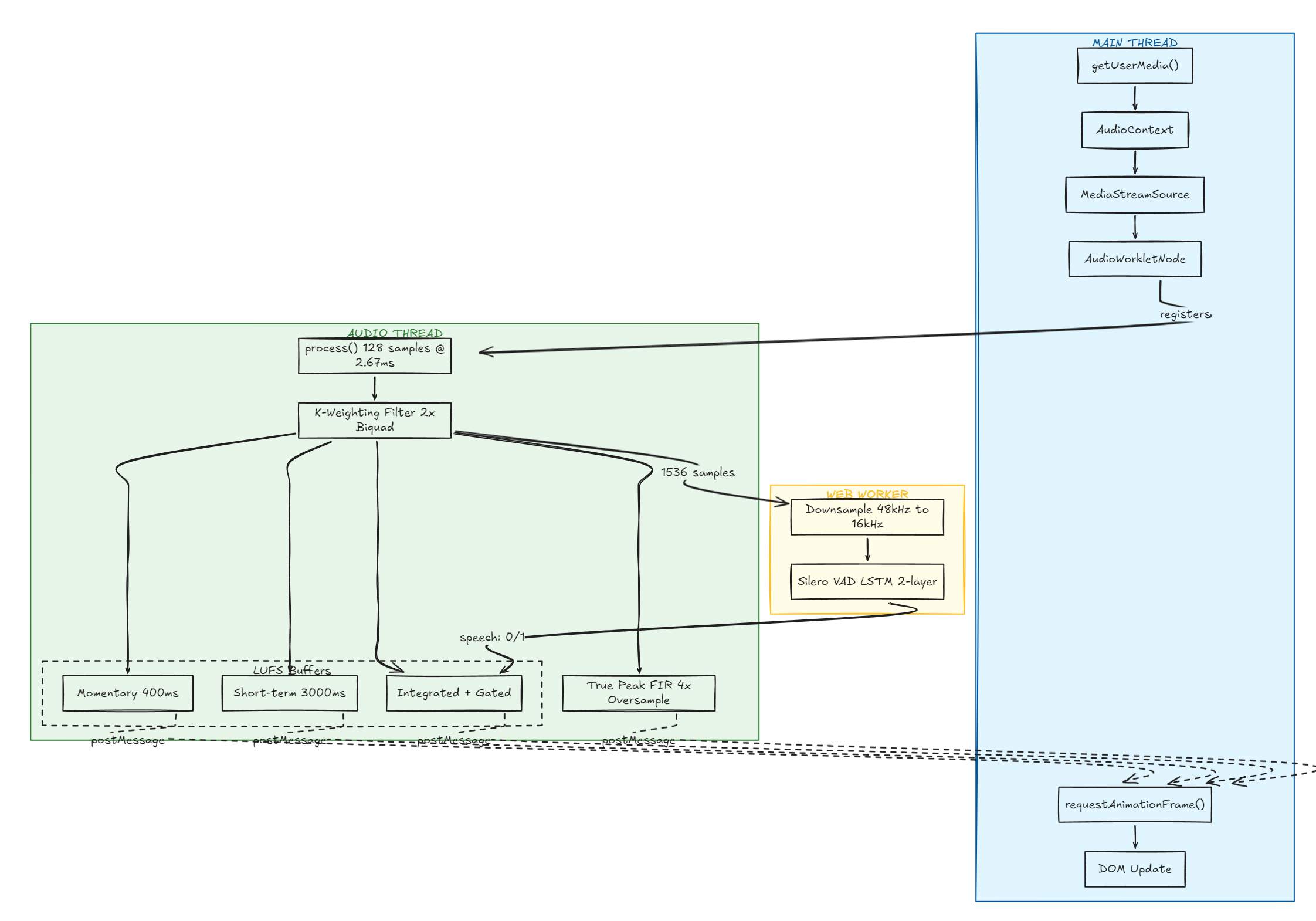
Microphone access and the audio graph
javascript is single-threaded. microphone access takes time, so it's promise-based via getUserMedia. without promises, the browser freezes.
const stream = await navigator.mediaDevices.getUserMedia({ audio: true })
const ctx = new AudioContext()
const source = ctx.createMediaStreamSource(stream)navigator is the global object representing browser capabilities. AudioContext is the audio-processing graph — audio modules linked together. createMediaStreamSource plugs the mic stream into that graph.
Audioworklet and threading
the audio runs on a dedicated real-time thread separate from the main js thread:
main thread → ui, dom, script.js
audio thread → audioworklet, process(), real-time audio
web worker → heavy computation (onnx inference for vad)postMessage is a thread-safe queue between the main thread and the audio thread. in the actual browser, the audio thread is a real os thread in c++, js runs there via v8 — the main thread never blocks.
the browser chunks audio input based on sample rate. audioworklet calls process() with exactly 128 samples every time:
128 samples at 48kHz = 2.67ms per call
128 samples at 44.1kHz = 2.90ms per callmic has a fixed clock (crystal oscillator). browser delivers data in these 128-sample blocks, non-negotiable.
K-weighting filter
k-weighting is a frequency weighting method for measuring perceived loudness. the human ear is non-linear — it gives more weight to higher frequencies. k-weighting models this.
two biquad filters applied in series:
- stage 1 — high shelf filter (pre-filter): boosts frequencies above ~1.5khz by ~4db
- stage 2 — high pass filter (rlb weighting): rolls off everything below ~38hz, removing sub-bass
each filter is a biquad with coefficients (b0, b1, b2, a1, a2). these are fixed constants from the itu-bs.1770 spec, and they differ by sample rate (48khz vs 44.1khz).
biquad difference equation:
y[n] = b0·x[n] + b1·x[n-1] + b2·x[n-2] - a1·y[n-1] - a2·y[n-2]where x = input samples (history), y = output samples (history).
the transfer function describes how the system responds to input in the z-domain — a ratio of polynomials relating input to output. we use it to analyze and design filters.
signal processing typically works with floats, not doubles or ints.
LUFs metering
Mean squaring
squaring makes everything positive and amplifies louder sounds more than quiet ones — which matches perception.
mean_square = sum(sample² for each sample in window) / num_samples
LUFS = -0.691 + 10 × log10(mean_square)the constant -0.691 comes from the spec to calibrate the scale. 0 lufs is the absolute maximum. normal speech and music lives around -23 to -14 lufs.
Momentary loudness
sliding window of 400ms, updated every 100ms (75% overlap).
bufferSize = sampleRate * 0.4 // 48000 * 0.4 = 19200 samples
hopSize = sampleRate * 0.1 // 48000 * 0.1 = 4800 samples
in dsp, 50% or more overlap is considered a good balance between time resolution and frequency resolution — minimizes artifacts and gives more accurate representation of rapidly changing signals.
samplesSinceLastReport counts samples inside process() because we have no clock there — we need to fire a lufs update every 100ms (every hopSize samples).
Short-term loudness
same as momentary but with a 3000ms (3s) window.
Integrated loudness
average over the entire program. itu adds two gating stages to exclude silence — pauses between words shouldn't drag the average down.
gate 1 — absolute gate: ignore any 400ms block below -70 lufs. pure silence excluded.
gate 2 — relative gate:
- calculate un-gated average (e.g. -18 lufs)
- threshold = un-gated average - 10 lu (e.g. -18 - 10 = -28 lufs)
- re-calculate average using only blocks above threshold
block stream: [-16, -17, -18, -50, -51, -17, -16]
throw away -50 and -51 (below -28 lufs)integratedBlocks grows forever. at 100ms per block, 1 hour = 36,000 blocks ≈ 288kb of memory. fine for browser use. production meters use a running sum instead of storing every block.
two separate buffers run in parallel — one for momentary, one for short-term. each has its own buffer, bufferSize, and samplesSinceLastReport. the k-weighted sample gets pushed into both every iteration. they share the same filter input but accumulate independently.
Why not peaks
a question comes up: how does integrated loudness handle loud transients when some blocks get discarded?
it doesn't — and that's fine. we're not trying to catch peaks. we're measuring average perceived loudness over time. a single loud transient lasts maybe 5-10ms, so it gets averaged into its 400ms block and its energy contribution is tiny.
this naturally leads to true peak, which is a separate measurement entirely.
True peak detection
streaming platforms convert digital audio to analog during playback. if the reconstructed waveform between samples exceeds 0 dbfs, you get distortion — inter-sample clipping.
time: 0ms 0.02ms 0.04ms
sample: 0.3 0.7 0.4
real waveform between samples:
0.3 → rises to 0.95 → falls to 0.7
↑ never capturedto see between samples, we oversample — inserting new interpolated samples between real ones.
original (1x): [0.3, 0.7]
4x oversample: [0.3, 0.52, 0.78, 0.95, 0.7]
↑ interpolatedFIR interpolation
not averaging — that's too limiting. we use a fir filter (finite impulse response): a set of fixed coefficients (taps).
itu-bs.1770 specifies exact fir coefficients for 4x oversampling — 48 coefficients. more taps = more accurate waveform reconstruction between samples, more computation per sample. we use 13 taps for a balance of accuracy and cost.
true peak buffer = sliding window of last raw samples
new sample → shift right → insert at index 0
[new, s1, s2, s3, s4, s5, s6, s7, s8, s9, s10, s11, s12]
convolve with fir coefficients = one interpolated peak value
new_sample = sum(original_samples[i] * fir_coefficients[i])3 phase offsets + real samples = 4 points checked per sample (true 4x oversampling):
real t=0.00: [0.3, 0.95, 0.4]
phase1 t=0.25: [0.61, 0.89, 0.55]
phase2 t=0.50: [0.71, 0.98, 0.61]
phase3 t=0.75: [0.85, 0.94, 0.48]truePeakMax starts at 0, only ever goes up. we care about magnitude not direction.
dBFS vs dBTP
dBFS → measures individual samples. max = 0 dBFS. nothing exceeds this digitally.
dBTP → measures the reconstructed analog waveform. CAN exceed 1.0 amplitude. CAN be positive.streaming platforms found that tracks measuring fine digitally were causing distortion on consumer dacs during digital-to-analog conversion. they mandated -1 dbtp maximum to leave headroom. the problem is not digital — it's the d/a conversion step.
Amplitude ↔ Power math
power = amplitude²
log10(amplitude²) = 2 × log10(amplitude)
dB = 10 × log10(power)
dB = 10 × 2 × log10(amplitude) = 20 × log10(amplitude)Visual metering
lufs is already a logarithmic unit, so a linear dbfs scale is perceptually correct for display.
range = 0 - (-60) = 60 units
currentLufs = -18 lufs
distance from bottom = -18 - (-60) = 42
percentage = 42/60 × 100 = 70% heightmeter bar grows from bottom. scale labels are positioned from top:
top: 0% → 0 lufs
top: 50% → -30 lufs
top: 100% → -60 lufsui lives on the main thread, audioworklet on the audio thread — they can't share memory directly. requestAnimationFrame runs ~60 times per second (every 16ms), picks up the latest lufs value sent via postMessage, and updates the dom.
Silero VAD integration
vad (voice activity detection) — binary output: 1 = speech, 0 = silence/noise.
we use silero vad (.onnx) via onnx runtime in a web worker. connecting it to the loudness meter means we only compute loudness metrics during active speech.
since we're not using a bundler, we load onnx via cdn using importScripts() — the web worker equivalent of <script> in html. workers have no dom, so importScripts() fetches and executes scripts synchronously inside the worker.
Downsampling
silero needs 16khz, 512-sample chunks. mic runs at 48khz. we need to downsample 3:1.
ratio = 48000 / 16000 = 3
→ keep every 3rd sample
512 samples at 16kHz × 3 = 1536 samples at 48kHz
collect 1536 raw samples
take index 0, 3, 6, 9 ... 1533 → 512 samples at 16kHzthis is decimation — discarding 2 out of every 3 samples. proper downsampling applies a low-pass anti-aliasing filter first to average the energy of those 3 samples into 1, rather than discarding 2. naive decimation introduces aliasing artifacts. for vad (detecting speech, not reconstructing audio), this is acceptable.
Silero LSTM
silero's lstm has 2 layers, 64 hidden units per layer, initialized to zero — no memory of previous audio at start.
lstm carries state between inputs:
chunk_1 → lstm → output, new_state
chunk_2 → lstm(new_state) → output, new_state
chunk_3 → lstm(new_state) → output, new_statetwo state vectors:
h— hidden state (short-term memory, what just happened)c— cell state (long-term memory, patterns over time)
without lstm, every 32ms chunk is judged in isolation. with it, the model understands continuity — "this is still speech" vs "silence starting."
Full pipeline delay
audio input
↓
128 samples arrive every 2.67ms (hardware clock, non-negotiable)
↓
process() runs, samples get k-weighted and pushed into buffer
cost: ~0.1ms
↓
buffer fills to 400ms worth of samples (biggest delay — itu spec)
↓
every 100ms (hopSize), lufs calculated, postMessage fires
wait: up to 100ms
↓
message crosses thread boundary
cost: ~0.1ms
↓
currentLufs updated
↓
rAF picks it up on next tick
wait: 0–16ms
↓
dom updates
worst case total: ~517ms
average total: ~450mshumans can't perceive display lag under ~100ms, so this is fine for a metering tool.
github.com/iam4tart/Loudness-QC-Tool