During our 3rd year, Priyodarshi Ghosh and I worked on something that pushed us as both engineers and researchers — Project Arya.
The Problem
Most NLP systems focus only on text. But stress doesn't always show up in words — it hides in tone, pauses, background sounds, even silence.
The question we started with: can machines detect stress not just from what you say, but how you say it and what's happening around you?
Step 1: Data
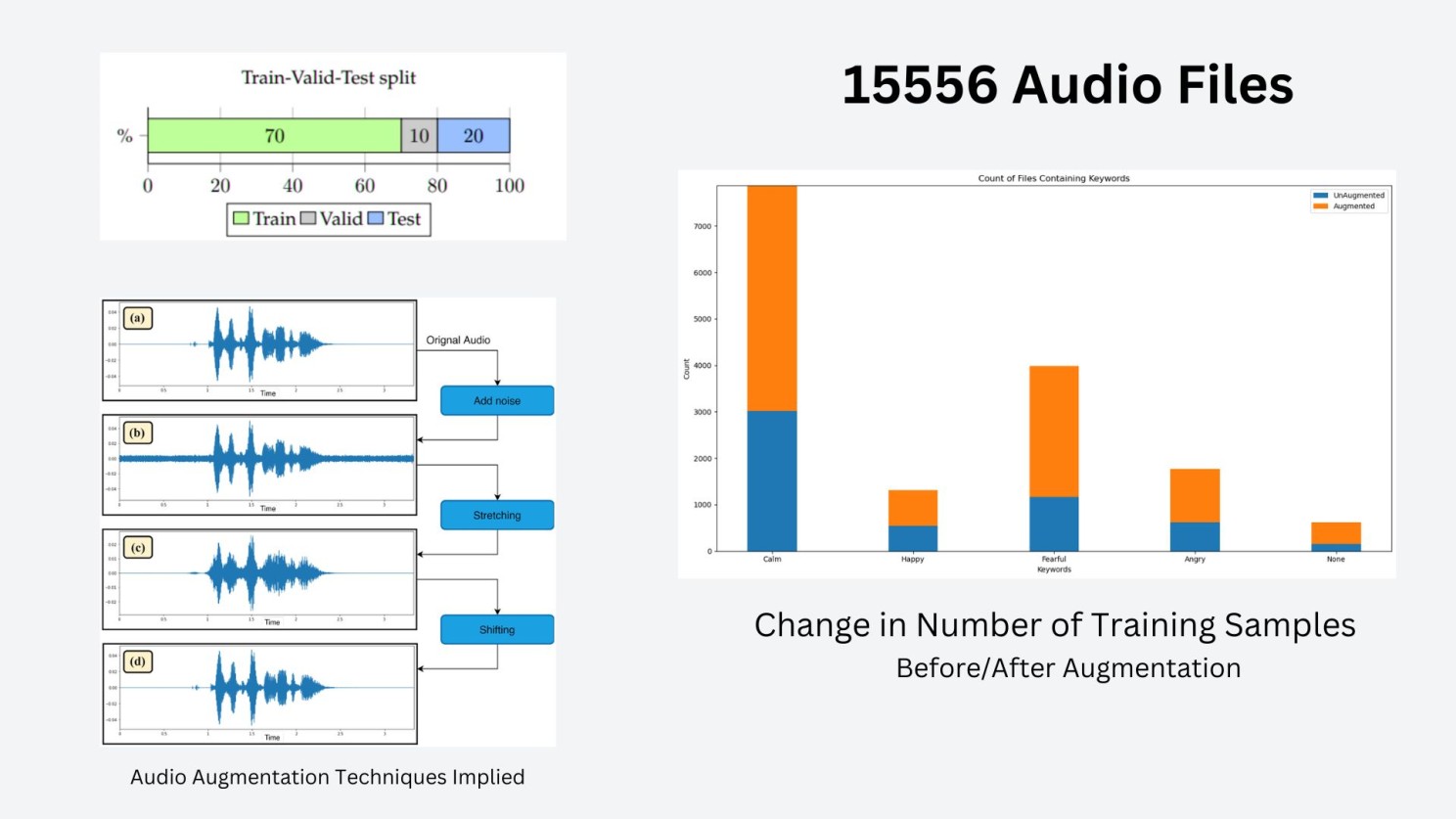
We settled on the Rakshak dataset — 5,505 audio clips recorded across natural and simulated environments, each labeled with a stress level (Safe / Not Safe), environment type, and keyword presence.

The dataset was too small for deep models, so we used Meta's AugLy to augment across three techniques — noise addition, time stretching, and pitch shifting — expanding it to 15,556 one-second clips.
import augly.audio as audaugs
import glob, os, random
def generate_nonzero_random():
rate = random.randint(-2, 2)
if rate == 0:
return 1
return rate
input_dir = "emodata/"
audio_files = glob.glob(os.path.join(input_dir, "*.wav"))
augmentation_folders = {
"noise": "emodata/augmented/noise/",
"timestretch": "emodata/augmented/timestretch/",
"pitchshift": "emodata/augmented/pitchshift/"
}
for augmentation_type, i_dir in augmentation_folders.items():
os.makedirs(i_dir, exist_ok=True)
for audio_file in audio_files:
file_name, file_ext = os.path.splitext(os.path.basename(audio_file))
if augmentation_type == "noise":
snr_level_db = random.uniform(5, 10)
output_file = os.path.join(i_dir, f"{file_name}{augmentation_type}{snr_level_db:.1f}{file_ext}")
aug_audio, sample_rate = audaugs.add_background_noise(
audio_file, sample_rate=None,
snr_level_db=snr_level_db, output_path=output_file
)
elif augmentation_type == "timestretch":
rate = random.uniform(0.5, 1.5)
output_file = os.path.join(i_dir, f"{file_name}{augmentation_type}{rate:.1f}{file_ext}")
aug_audio, sample_rate = audaugs.time_stretch(
audio_file, sample_rate=None,
rate=rate, output_path=output_file
)
elif augmentation_type == "pitchshift":
n_steps = generate_nonzero_random()
output_file = os.path.join(i_dir, f"{file_name}{augmentation_type}{n_steps:.1f}{file_ext}")
aug_audio, sample_rate = audaugs.pitch_shift(
audio_file, sample_rate=None,
n_steps=n_steps, output_path=output_file
)Each augmented file is named with its technique and parameter appended — e.g. yes-scream-fearful-..._noise_8.8.wav — making the augmentation type and intensity traceable from the filename alone. Augmentation introduced some keyword bias toward certain stress classes, which we cleaned by removing extreme outliers to preserve distribution integrity.
Step 2: Feature Engineering
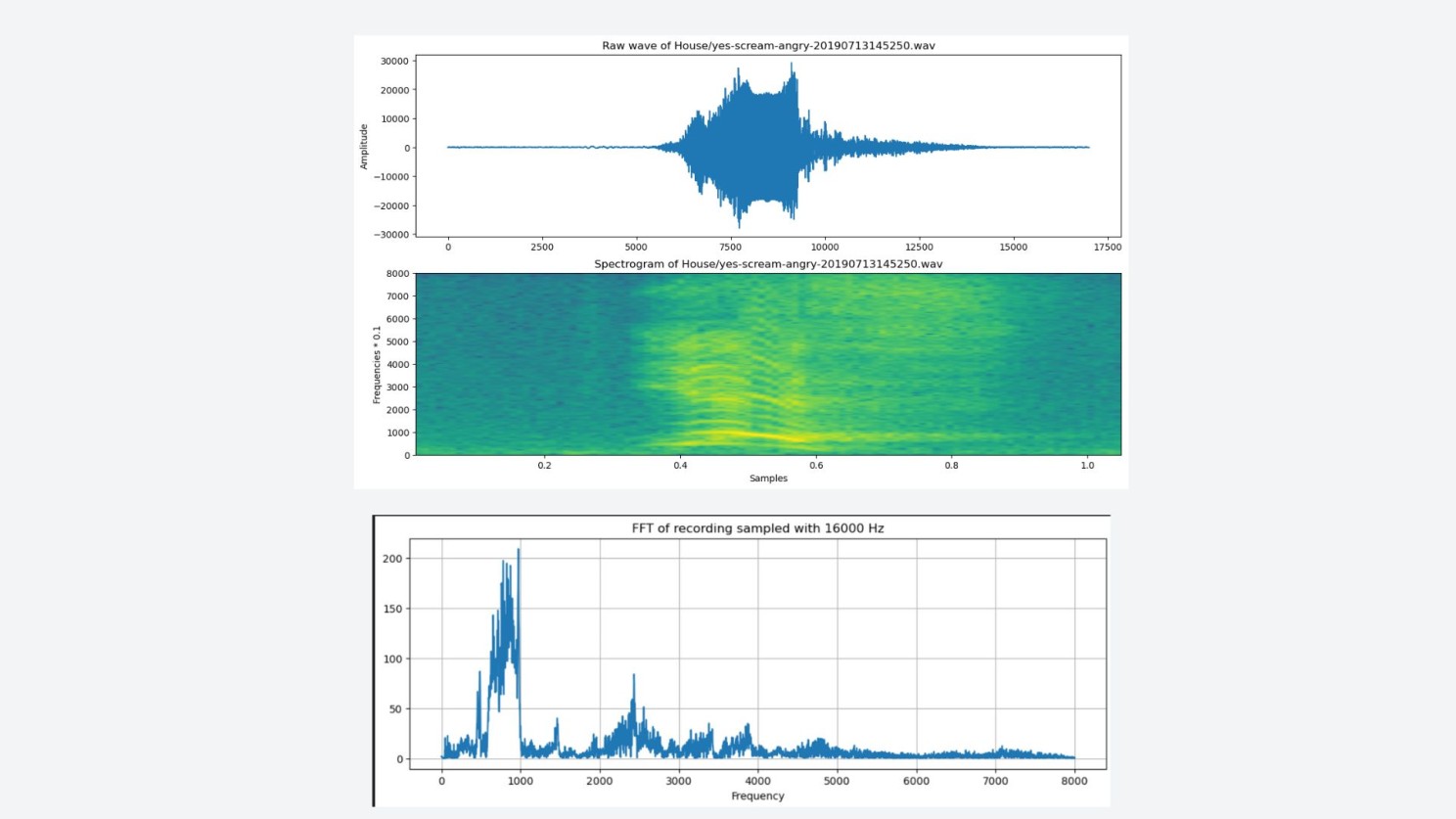
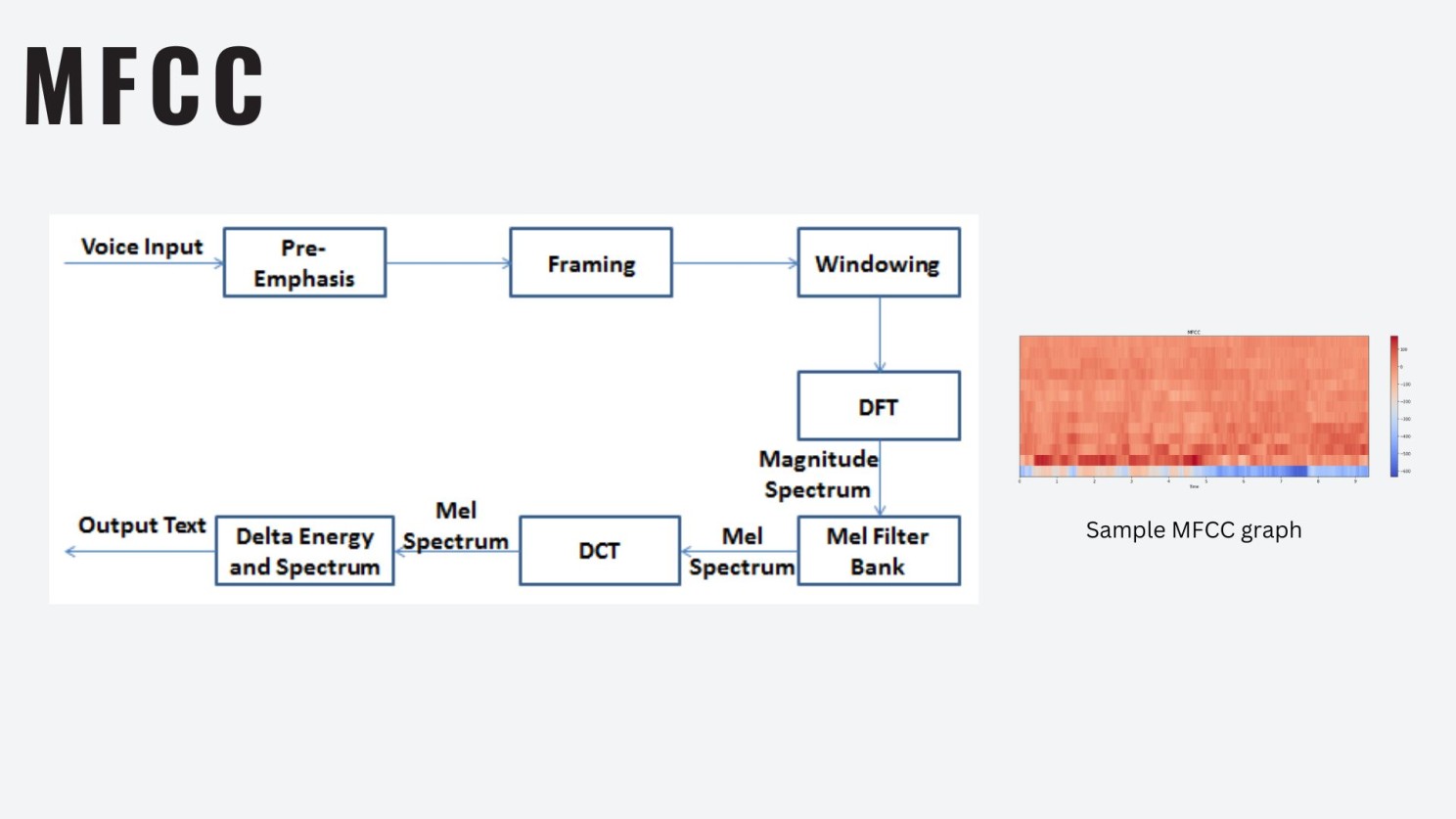
We extracted both low-level and high-level features:
- MFCCs — frequency envelope
- Spectral Centroid, ZCR — temporal dynamics
- Formants, Pitch, Jitter, HNR — vocal stress indicators
These were fed into LSTM, CNN, ResNet50, and EfficientNetB0. Results were satisfactory but not compelling — which pushed us toward transformers.
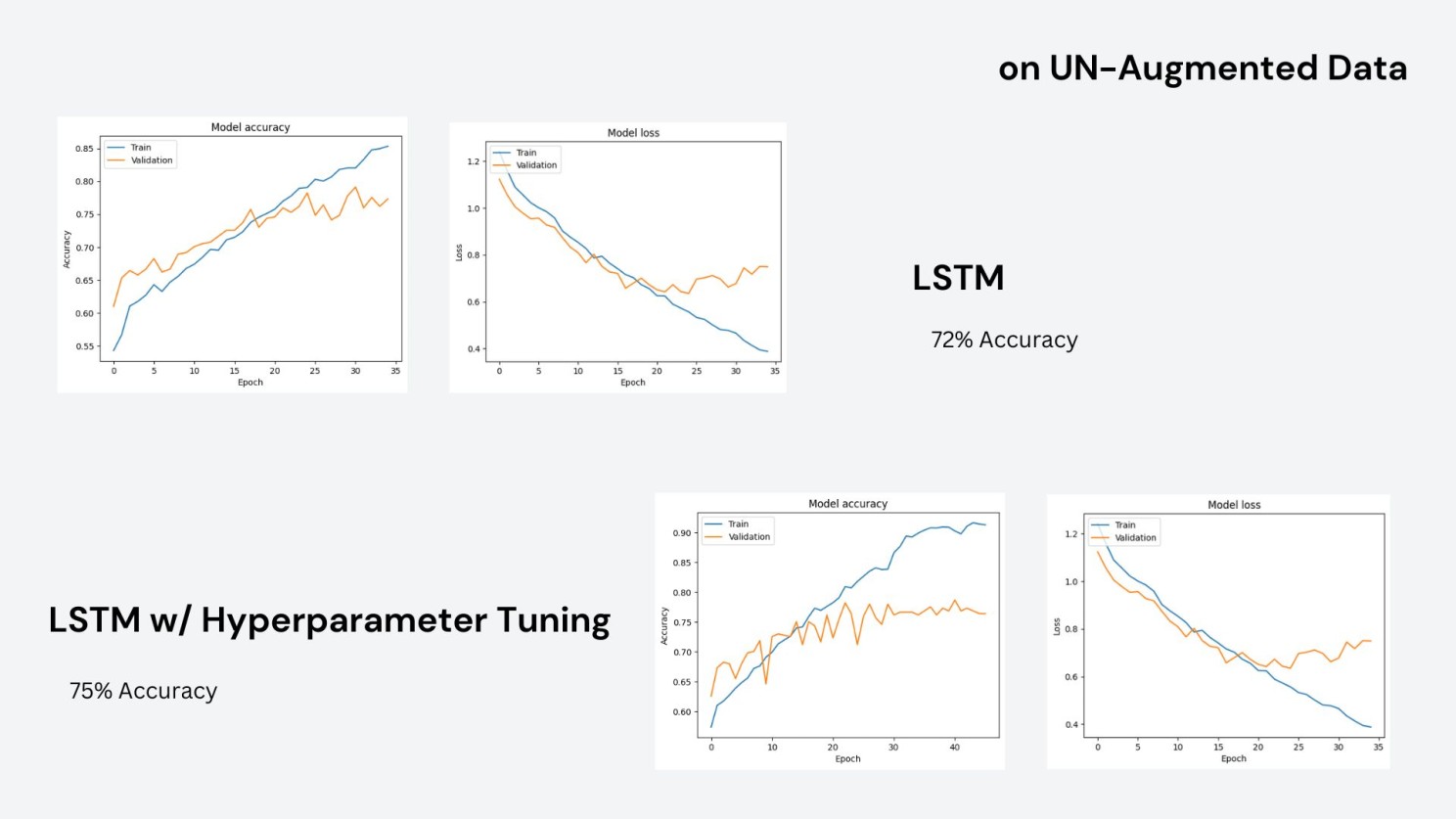
Step 3: Results on Classical Models
On un-augmented data, LSTM reached 72% accuracy. With hyperparameter tuning it pushed to 75%, but validation loss remained noisy — a sign the dataset size was the bottleneck.
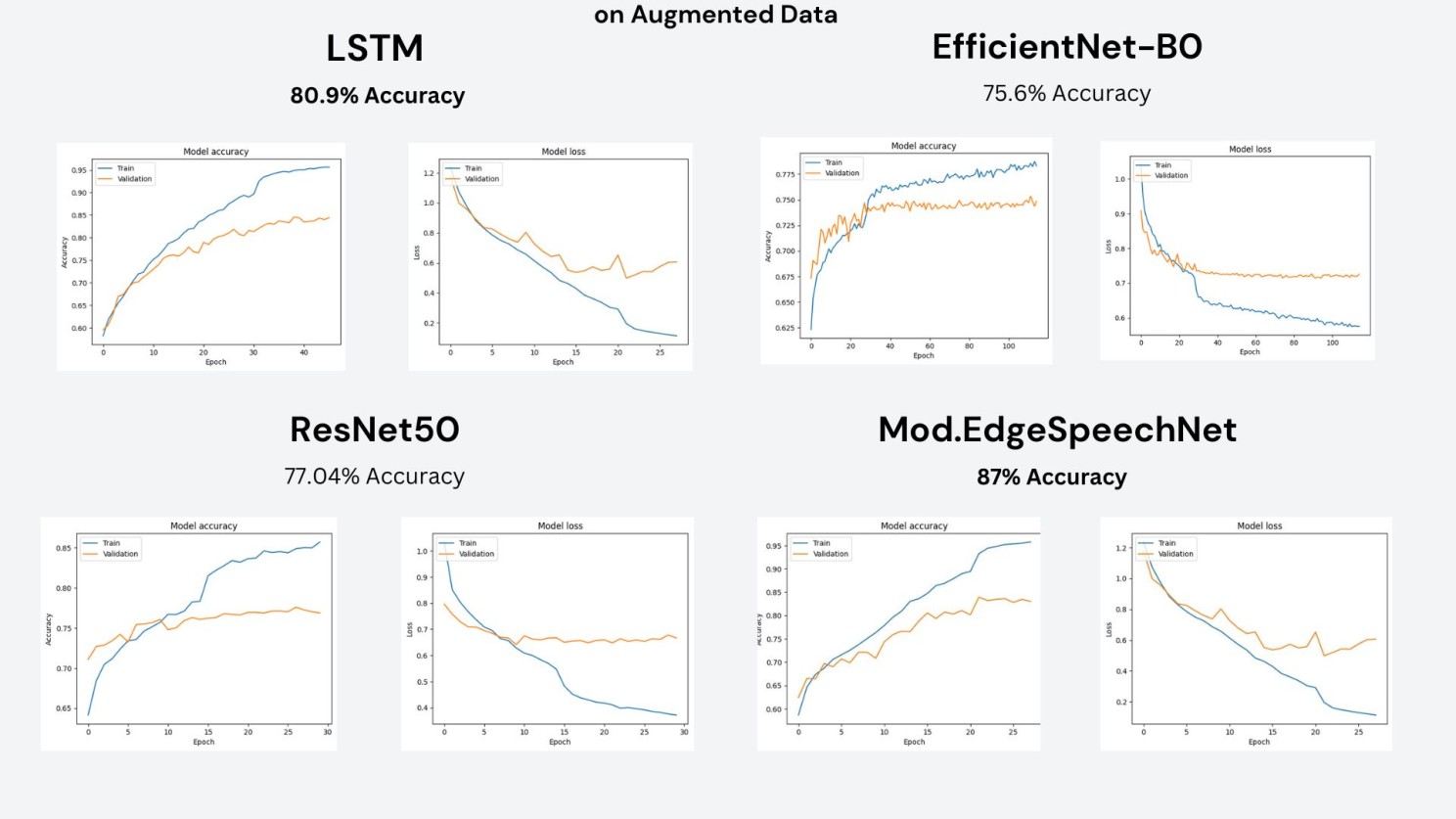
On augmented data, results improved across the board. Modified EdgeSpeechNet was the strongest at 87%, followed by LSTM at 80.9%, ResNet50 at 77%, and EfficientNetB0 at 75.6%.
Step 4: Transformer Pipeline
We wanted context-aware understanding beyond signal-level patterns, so we designed a multi-transformer pipeline where each component captures a different facet of stress.
Audio Separation
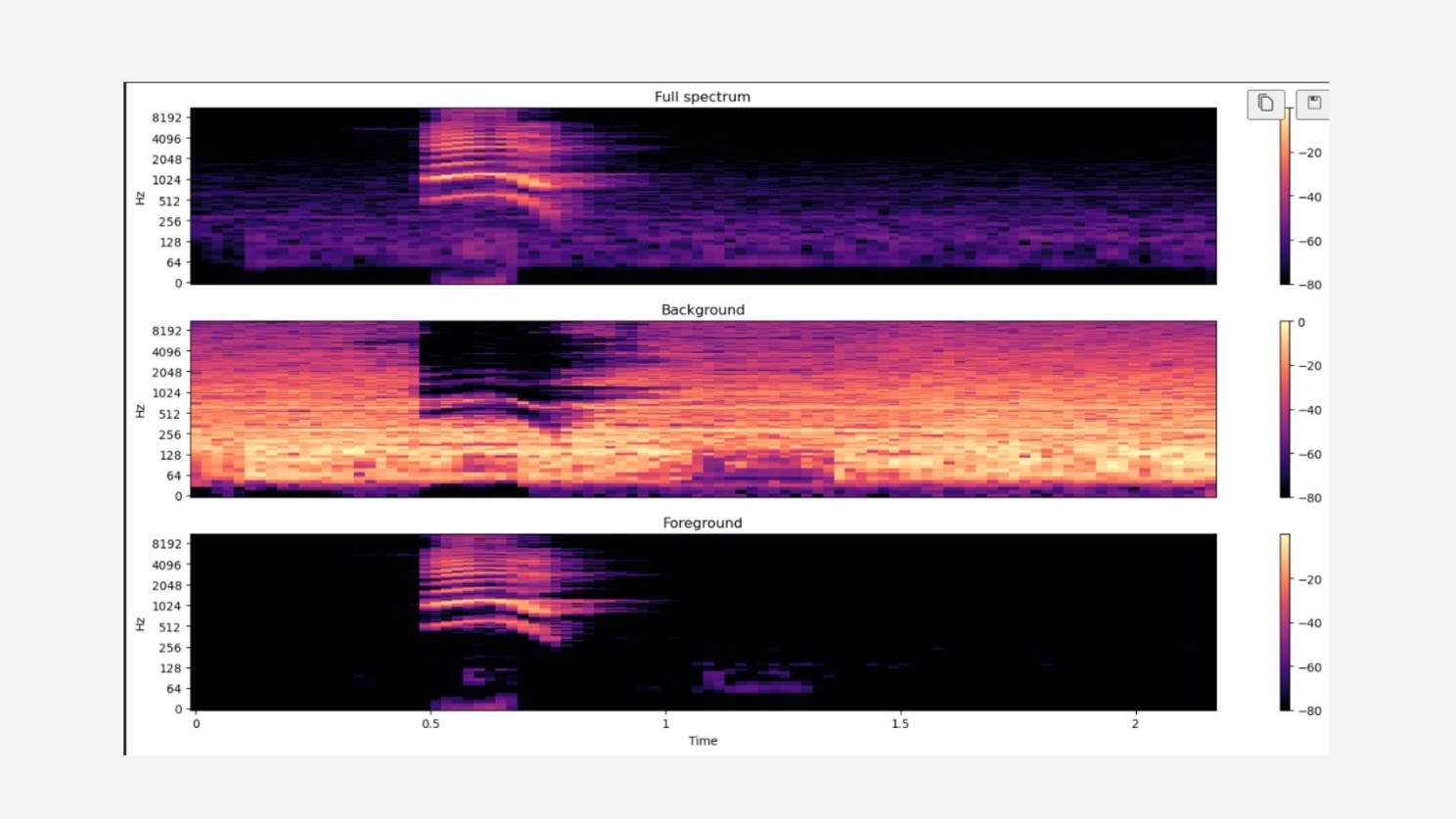
Coming from a music production background, we used Open-Unmix to separate the audio into speech and ambient signals — without discarding the ambient cues that most denoising models throw away. Those residuals mattered to us.
Transformer Stack
- Ambient signal → Audio Scene Classifier (MIT's AST model, trained on Google AudioSet) → environment composition vector (e.g., siren: 0.30, traffic: 0.20)
- Speech signal → Transcript Generator (what was said) + Speech Emotion Recognition Transformer (how it was said) → emotion distribution (e.g., happy: 0.74, disgust: 0.20) — benchmarked at ~83.6% on SER datasets
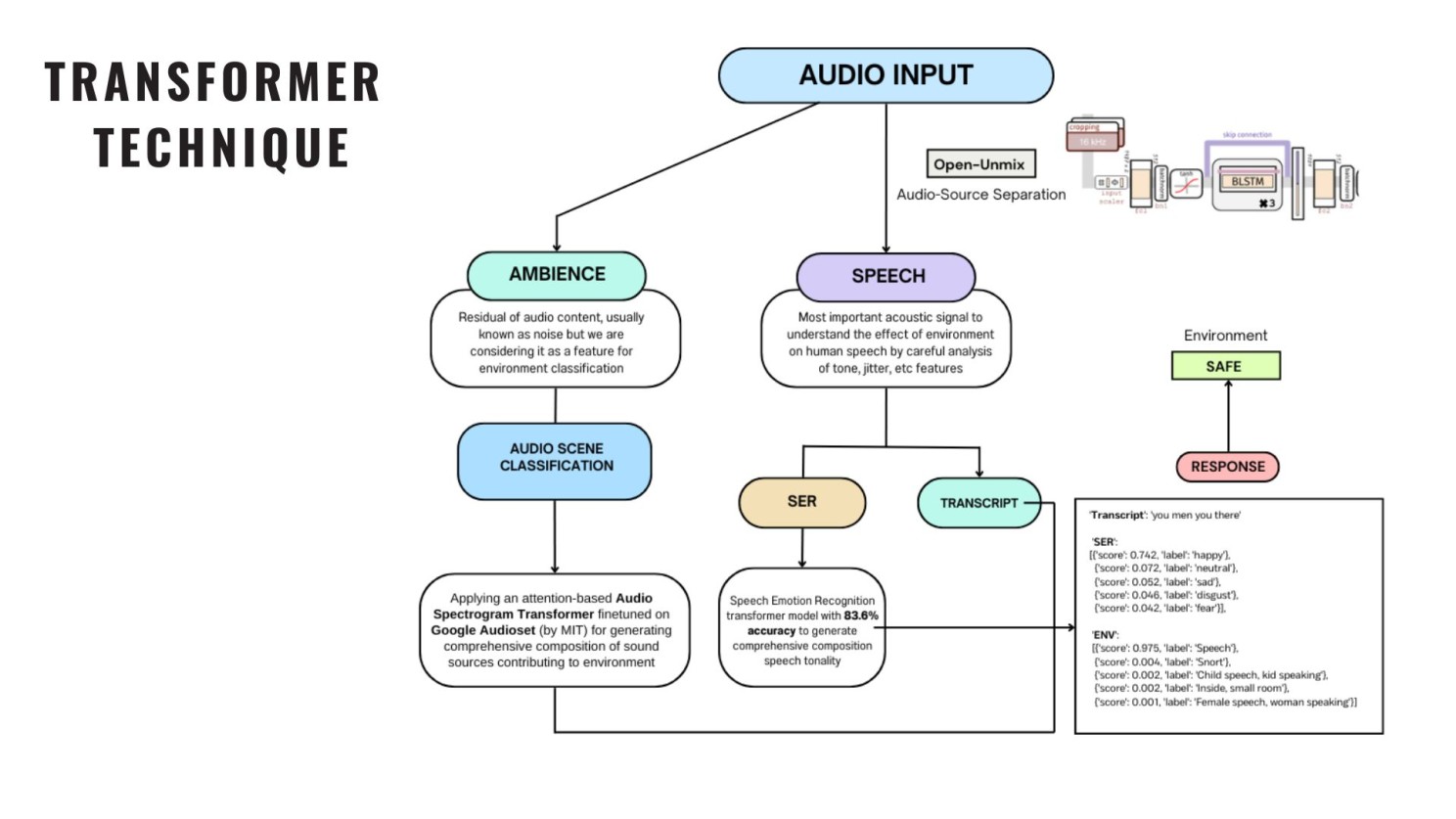
Step 5: Fusion and Classification
Transcript, emotion tensor, and environment scores were combined into a unified vector and fed into a final classifier predicting Safe or Not Safe. A high-stress output can trigger emergency flags or dynamically adapt a voice assistant's response.
Evaluation metrics used:
- Accuracy and F1 score for classification
- SNR / SDR / SAR for separation quality
- PEASS Toolkit planned for perceptual evaluation
What Didn't Work Well
- Some augmented samples introduced class bias
- Audio separation occasionally lost emotional nuance in the speech signal
- One-second clips missed emotional and word buildup over time
- Fusion of heterogeneous outputs needs more training cycles to generalize
Future Work
- BERT embeddings for transcripts concatenated with emotion and environment tensors
- Multiclass stress labels instead of binary Safe / Not Safe
- Multimodal cues — gestures, video, biosignals
- Real-time deployment optimization
Project Arya taught us that stress is subtle, multi-layered, and deeply contextual. To truly understand it, machines need to go beyond words.